
Running Development/Compilation Jobs:
Users can perform initial project setup and development on their local development nodes. Once the project is ready to be built, users can upload their projects to the cluster via the web-interface or SCP (SSH secure file copy).
Users can then run their compilations on the development server. You can access the development server via SSH from a login node.
- xacc-head-000-5.csl.illinois.edu
Users inside UIUC, may directly log SSH into the nodes as follows:
ssh <xacc-username>@xacc-head-000-5.csl.illinois.edu
Please be considerate of other users and do not oversubscribe resources.
NOTE: In the future direct SSH to the development node may be disabled, and users may need to request time on the node via the scheduler.
Running Compute Jobs:
HACC cluster uses the the Slurm job scheduler to manage resources. Here is a command cheat sheet for using slurm. Or you may refer to their quick start user guide.
In order to run an accelerated task, i.e. use an FPGA or GPU, you must submit a job request to the scheduler, by requesting how much time you want, what type of resources you require, and how many nodes you need.
Resource management:
HACC resources are virtualized, such as that, a single physical node has multiple VMs running on it, with a single FPGA/GPU allocated per VM. When your job is scheduled, an entire VM is exclusively allocated to your job. Once your job completes, the VM is released and another job maybe scheduled on it. For a list of all available nodes (VM and non-VM) nodes, please check the cluster status page.
Resources on HACC are managed in multiple job queues or resource partitions. Once you log into the login nodes, or a development node, you may submit jobs to these queues. In order to see what job queues you have access to, you may run the command:
sinfo
The result should look something like this:
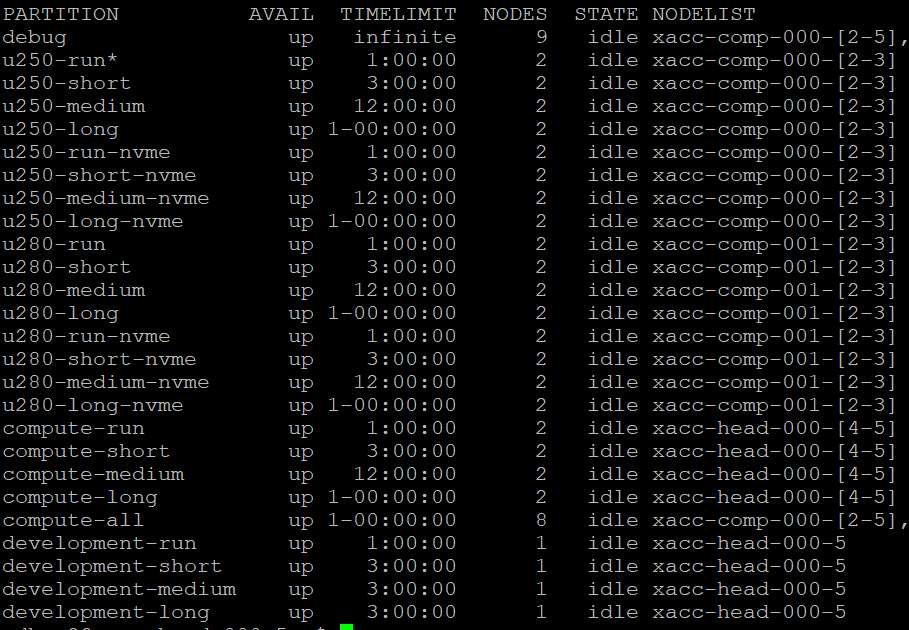
Note that each job queue has a unique set of resources. For example, if you need to run a job on an Alveo U280, you will need to request a job on a queue labeled “u280-xxx”. Each queue has different time limits as well. So a job on u280-run can run for up to 1 hour, while a job in u280-short can run for up to 3 hours.
Writing a job script and submitting jobs:
Please refer to the SLURM user guide on how to write a job script. To get you started, here is a basic job script. Before you run your job, keep in mind:
- Your environmental variable will be copied from the submission node.
- Always use FULL paths in your scripts
- Make sure your script runs your code in the correct directory
- Make sure to source the XRT libs inside your script
Here is a sample script to run the basic xrt validate utility:
### alveo_test.script ### #!/bin/sh source /opt/xilinx/xrt/setup.sh xbutil validate
You can then submit the hob and run it on an Alveo U250 by submitting it to one of the Alveo queues. For example:
sbatch -p u250-run alveo_test.script
You may provide many more options to the sbatch command to determine the name of your job, the number of requested nodes, error management etc. For details, please refer to the SLURM documentation.
NOTE: Jobs can be submitted from login nodes or the development node.
Once a job is complete, your output is saved to a run log named slurm-<jobid>.out in your home directory by default. You may change the name and location of this via the job script.
You can monitor the state of your submitted jobs via
squeue
Interactive jobs
It is possible to request an interactive job. This will log you directly into a compute node, without the need to write a job script. Once logged in, you can interact with the node and run as many commands as you’d like within the allotted time limits. Please refer to the SLURM documentation on how to run interactive jobs. As an example, to interact with the U280 nodes:
srun -p u280-run -n 1 --pty bash -i